LLMアプリケーションの作り方
LLMアプリケーションを作るには下図のように多くの工程があり、さまざまな技術やツールが必要です。これらはまとめてLLMOps(LLM Operations:大規模言語モデル運用)とも呼ばれています。
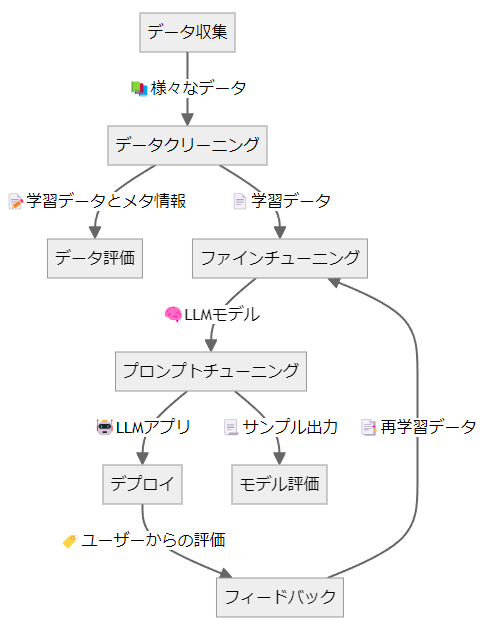
このドキュメントでは、LLMアプリケーション開発の全体像を把握するために、LLMOpsの内容とそれに対応するMDKの機能について概説します。
データ収集
深層学習モデルの開発はデータセットの収集から始まります。LLMのファインチューニングをするには特に、LLMに回答してほしい文体や情報を含むドキュメントを収集する必要があります。データ収集は本質的なタスクであり、作りたいモデルによって収集方法が大きく異なるのでMDKはデータ収集の機能自体は持っていません。MDKの各機能を利用してLLMOpsの他の工程を高速化することで、ユーザーはデータ収集に注力することができます。
データクリーニング
データを集めただけではモデルの学習には使用できず、適切な前処理を行って学習可能なフォーマットに揃える必要があります。たとえばalpacaデータセットのような質問回答データはSFT(Supervised Fine-tuning)、あるいはhh-rlhfデータセットのような選好データはDPO(Direct Preference Optimization)という方式でそれぞれLLMに学習させることができます。MDKのdataset_converterを利用すると、多様な入力フォーマットそれぞれに合わせた前処理が自動で実行されて、SFTやDPOに合わせたフォーマットで出力します。
データ評価
自動で作成したデータセットには、文法的な誤りや事実とは異なる情報が含まれている可能性があります。これらを完全に除去するのは手間がかかる作業ですが、MDKではdataset_evaluatorとmanual_dataset_evaluatorという2種類のモジュールを用いて自動あるいは手動でのデータセット評価を行うことができます。データ評価の結果が不十分である場合は、データ収集やデータクリーニングの手法を見直すことになります。
ファインチューニング
データクリーニングが完了すると、モデルの学習を実行することができます。学習には大規模な計算資源が必要で、効率的なハードウェアの利用が求められます。MDKではtrainerがDeepSpeed ZeROとLoRAを用いたSFTに対応しており、効率的な学習を簡単に実行することができます。
プロンプトチューニング
信頼できるLLMアプリケーションを作るためにはモデル本体だけでは不十分であり、適切なプロンプトチューニングやRAGを適用する必要があります。MDKのlauncherはプロンプトチューニングやRAGに適したアプリケーションを提供しています。
デプロイ
アプリケーションが完成すると、ウェブアプリケーションとしてデプロイすることができます。launcherはvLLMを利用して構築されており、高い並列度でモデルを提供することができます。
モデル評価
LLMアプリケーションは評価指標が多岐にわたるため難易度の高いタスクの一つです。MDKではlauncherを利用して複数モデルを同時に推論・比較することができ、定性的な判定をすることができます。また、model_evaluatorを利用して自動かつ定量的にモデルを評価することもできます。
フィードバック
アプリケーションの利用者から良い回答・悪い回答についてのフィードバックを収集することで、trainerを使ってDPOで学習してモデルの質をさらに高めることができます。
パイプライン
各タスクは密接に関係しており、それぞれのタスクを自動化するためのパイプラインを利用することで効率的にモデルの学習をすることができます。MDKではpipelineモジュールがそれぞれのタスクを連続して実行するパイプラインを提供しています。