CUDA out of memoryエラーに対応する
学習や推論・評価の作業中に、下記のようなCUDA out of memory(OOM)エラーが発生することがあります。
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 6.37 GiB. GPU 0 has a total capacty of 79.11 GiB of which 2.93 GiB is free. Including non-PyTorch memory, this process has 76.17 GiB memory in use. Of the allocated memory 68.61 GiB is allocated by PyTorch, and 5.63 GiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
このエラーはGPUメモリが用意された量より多く使用されたことを表していて、いくつかの原因が考えられます。このドキュメントでは、CUDA out of memoryの主な原因と対策について説明します。
前提条件
サーバーの初期設定が済んでおり、Python・CUDA・CUDNNなどが利用可能な状態になっている必要があります。
原因1.他のユーザーと同じGPUを使っている
まずnvitop(チュートリアルの環境構築が完了していない場合はnvidia-smi)コマンドを利用して、GPUの利用状況を確認します。GPUが他のユーザーに使用されている場合は通常同じGPUを使うことはできず、実行時にCUDA out of memoryエラーが発生します。
| 空き | 使用中 |
|---|---|
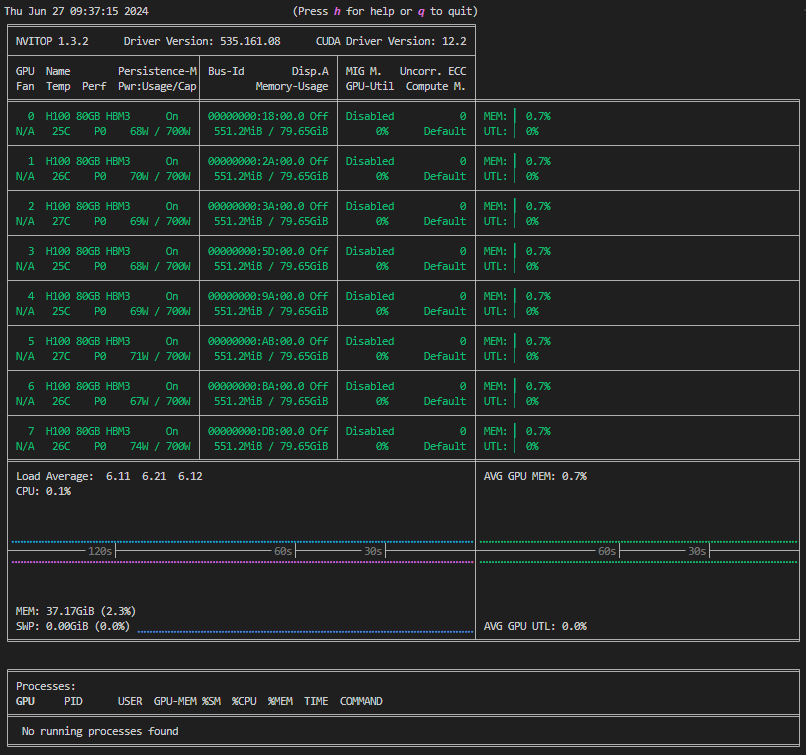 | 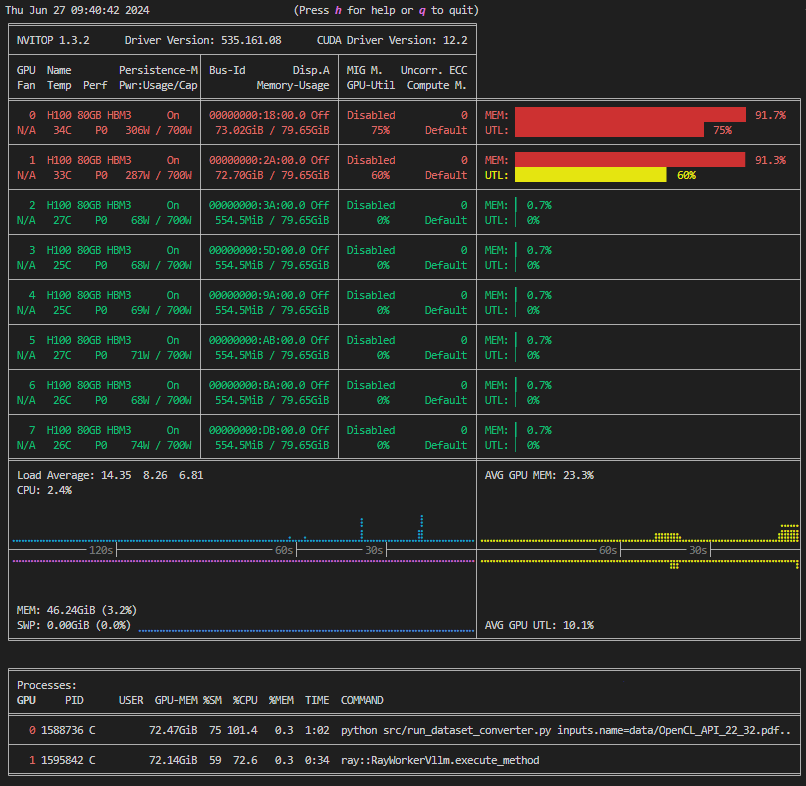 |
原因2.システムで使用可能な範囲より大きいモデルを使っている
タスクによっては必要なメモリサイズが非常に大きく、GPUが空いていても処理を実行できない可能性もあります。MDKで実行できる主なタスクとその使用メモリは以下の通り、主にモデルサイズ(1B=10億パラメータ)に依存して決まっています。
| システムの構成 | GPUメモリ合計 | 通常学習(LoRA) | FP16推論 | モデル評価 | フルパラメータ学習 |
|---|---|---|---|---|---|
| H100x8 | 640GB | 70B | 70Bx4 | 70B | 7B |
| H100x4, A100x8 | 320GB | 30B | 70Bx2 | 30B | - |
| H100x2, A100x4 | 160GB | 13B | 70B | - | - |
| H100x1, A100x2 | 80GB | 7B | 30B | - | - |
対策1. CUDA_VISIBLE_DEVICES変数を使う
上の「使用中」の図では、GPU0,1が使用されており、GPU2~7は空いている状態です。実行したいタスクがシステム全体を使うものではなく、この図のように空きGPUが存在する場合は、CUDA_VISIBLE_DEVICES変数を使用して別のGPUにタスクを割り振ることができます。
# GPU2,3を使用してdataset_converter(推論)を実行する
CUDA_VISIBLE_DEVICES=2,3 python src/run_dataset_converter.py inputs.name=data/OpenCL_API_23_32.pdf
対策2.モデルを変更する
原因2が当てはまる場合は、タスクのパラメータを変更することで対応します。とくに、モデルサイズを小さいものに変えると少ないGPUで動くようになりますが、学習後の精度にも大きく関わるパラメータなので適切な設定が必要です。
# 70Bモデルから8Bモデルに変更してtrainerを実行する
CUDA_VISIBLE_DEVICES=0 deepspeed --hostfile=/dev/null src/run_trainer.py config/trainer/Llama-3-8b.yaml dataset.data_files=data/OpenCL_API.jsonl
タスクによってはモデル名だけでなく各種パラメータも同時に変更する必要があります。詳細は各種ドキュメントや設定ファイルを参照ください。
# 70Bモデルから8Bモデルに変更してdataset_converterを実行する
CUDA_VISIBLE_DEVICES=0 python src/run_dataset_converter.py inputs.name=data/OpenCL_API_23_32.pdf llm.model=meta-llama/Meta-Llama-3-8B-Instruct llm.vllm_tensor_parallel_size=1
対策3.問い合わせる
上記対応ができない場合は、既に使用中のユーザーや管理者に問い合わせてリソースを調整してください。