人力評価してフィードバックするチュートリアル
単純に自動評価をするだけでは、評価結果自体にも誤りが含まれている可能性があります。
このチュートリアルでは、そのような自動評価結果の誤りを訂正し、よりよいデータセット生成とモデル評価を実施しましょう。
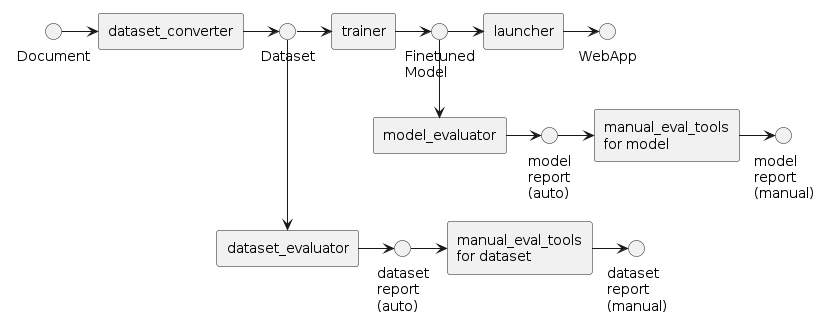
前提条件
以下のチュートリアルが完了していることが必要です。
また、上記チュートリアルで実施したようにnvitopコマンドを利用してGPUが空いていることを確認してください。
データセットの人力評価
データセットを人力評価することで、モデルの精度を改善したり、dataset_evaluator自体の精度を検証することができます。
まず、次のコマンドを入力してUIを起動します。
$ python src/run_manual_dataset_evaluator.py outputs/dataset_evaluator/<YYYY-MM-DD>/<HH-MM-SS>/experiment_log.json
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
起動後、ポート転送を使うとhttp://localhost:7860から、下記のような画面で生成された質問回答を確認することができます。 ただしFAIBサーバーにはファイアーウォールが設定されておりポート7860に直接アクセスできないため、説明書を参照してポート転送してください。
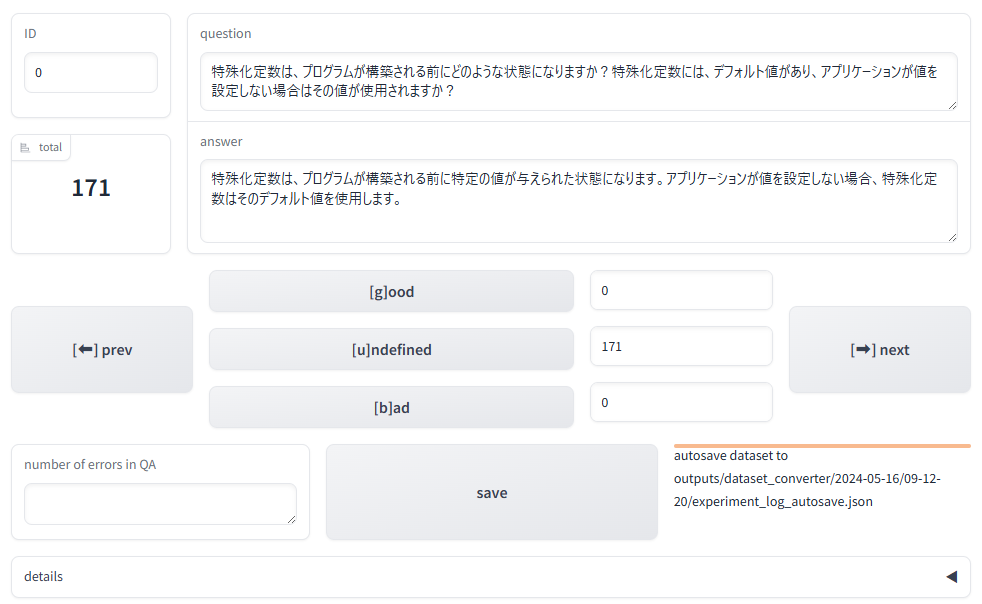
評価結果の修正
totalには質問回答の総件数が表示されます。dataset_evaluatorが質問回答を評価した結果は、画面左下のnum_error欄に記載されています。中央下のボタンは質問回答の手動評価に使用します。また、各手動評価ボタンの右には、評価の件数が表示されます。
experiment_log.jsonと同じディレクトリ内に、手動保存したexperiment_log_manual_<YYYY-MM-DD-HH-MM-SS>.jsonが存在する場合はそのうち最新のものが優先して読みこまれます。そうではなくて自動保存されたexperiment_log_autosave.jsonが存在する場合はそれが読みこまれます。どれも存在しない場合は無印のexperiment_log.jsonが読み込まれます。(途中まで評価結果を修正した場合に、saveしておくことで、途中まで評価したログを読み込むことが可能になります)
IDに数値を指定して、リターンキーを押下すると、そのIDの質問回答に遷移しますgoodボタンを押すと質問回答は正しい(num_errorが0である)とみなして、次の質問回答に遷移しますundefinedボタンを押すと質問回答は未回答(num_errorがNoneである)とみなして、次の質問回答に遷移しますbadボタンを押すと質問回答は誤り(num_errorが1である)とみなして、次の質問回答に遷移しますnextボタンを押すと次の質問回答に遷移しますprevボタンを押すと前の質問回答に遷移しますsaveボタンで評価結果を保存します
各ボタンはキーボードショートカットがあります。
| ボタン | キー |
|---|---|
good | g |
undefined | u |
bad | b |
next | 方向キー(右) |
prev | 方向キー(左) |
その他の機能については手動評価UIを利用するハウツーを参照してください。
質問回答の修正
質問回答そのものを修正したい場合は、画面上のテキストボックスを直接書き換えてください。隣の質問回答に遷移する(good,bad,next,prevいずれかのボタンを押す)と、更新された質問回答がメモリに保存されます。
人力評価結果をフィードバックする
最後にsaveボタンを押すと、experiment_log_manual_<YYYY-MM-DD-HH-MM-SS>.jsonとdataset_manual_<YYYY-MM-DD-HH-MM-SS>_<judge>.jsonlという2種類のファイルが出力されます。各ファイルの使い方は次の通りです。
jsonファイルをdataset_evaluatorの評価に使用する

src/run_dataset_evaluator.pyにjsonファイルを渡すと、質問回答の自動評価が再度実施され、手動評価の結果との一致率を見ることができます。
$ python src/run_dataset_evaluator.py inputs.name=outputs/dataset_evaluator/<YYYY-MM-DD>/<HH-MM-SS>/experiment_log_manual_<YYYY-MM-DD-HH-MM-SS>.json output.confusion_matrix=confusion_matrix.csv
[2024-03-27 20:16:32,238][preprocess.llm][INFO] - init PreprocessWithLLM: 73.358783 sec
Processed prompts: 100%|███████████████████████████████████████████████████████████████████████████████████| 406/406 [03:00<00:00, 2.25it/s]
[2024-03-27 20:19:33,508][preprocess.evaluate][INFO] - evaluate_dataset: 181.263905 sec / 406 QAs = 0.446463 sec/QA
[2024-03-27 20:19:33,584][preprocess.evaluate][INFO] - clean QA: 208 / 406 (51.231527 %)
[2024-03-27 20:19:33,587][preprocess.evaluate][INFO] - wrong QA: 133 / 406 (32.758621 %)
[2024-03-27 20:19:33,588][preprocess.evaluate][INFO] - invalid QA: 65 / 406 (16.009852 %)
[2024-03-27 20:19:33,612][preprocess.evaluate][INFO] - accuracy: 0.514778
[2024-03-27 20:19:33,612][preprocess.evaluate][INFO] - precision: 0.586466
[2024-03-27 20:19:33,612][preprocess.evaluate][INFO] - recall: 0.503226
[2024-03-27 20:19:33,612][preprocess.evaluate][INFO] - f1: 0.541667
[2024-03-27 20:19:33,615][preprocess.evaluate][INFO] -
| | clean | wrong | unknown |
|:--------|--------:|--------:|----------:|
| clean | 131 | 77 | 0 |
| wrong | 55 | 78 | 0 |
| invalid | 30 | 35 | 0 |
[2024-03-27 20:19:33,616][__main__][INFO] - execution time: 254.736552 sec
手動評価が実施されなかったものはunknownという分類がされます。
混同行列は各行(invalidがある)が自動評価、各列(unknownがある)が手動評価です。
jsonlファイルをtrainerに使用する

出力されるjsonlファイルは評価のチュートリアルと同様にclean,wrong,invalidという評価名がついています。
各jsonlファイルは、学習のチュートリアルでのdataset.data_filesで指定することでそのまま利用できます。
ただし、同じモデルに対してもう一度学習する場合は、training_args.output_dirを指定するのを忘れないようにしてください。
複数の手動評価の結果をtrainerに使用するには、手動評価結果をデータセットに変換するハウツーを参照してください。
属性評価のスコアグラフを描画する
手動評価結果を利用すると、自動評価結果と比較するグラフの描画も実施できます。詳細は評価指標の設定資料を参照してください。
モデルの人力評価
promptfooのウェブUIを使って、自動評価の結果を訂正することができます。
promptfoo view
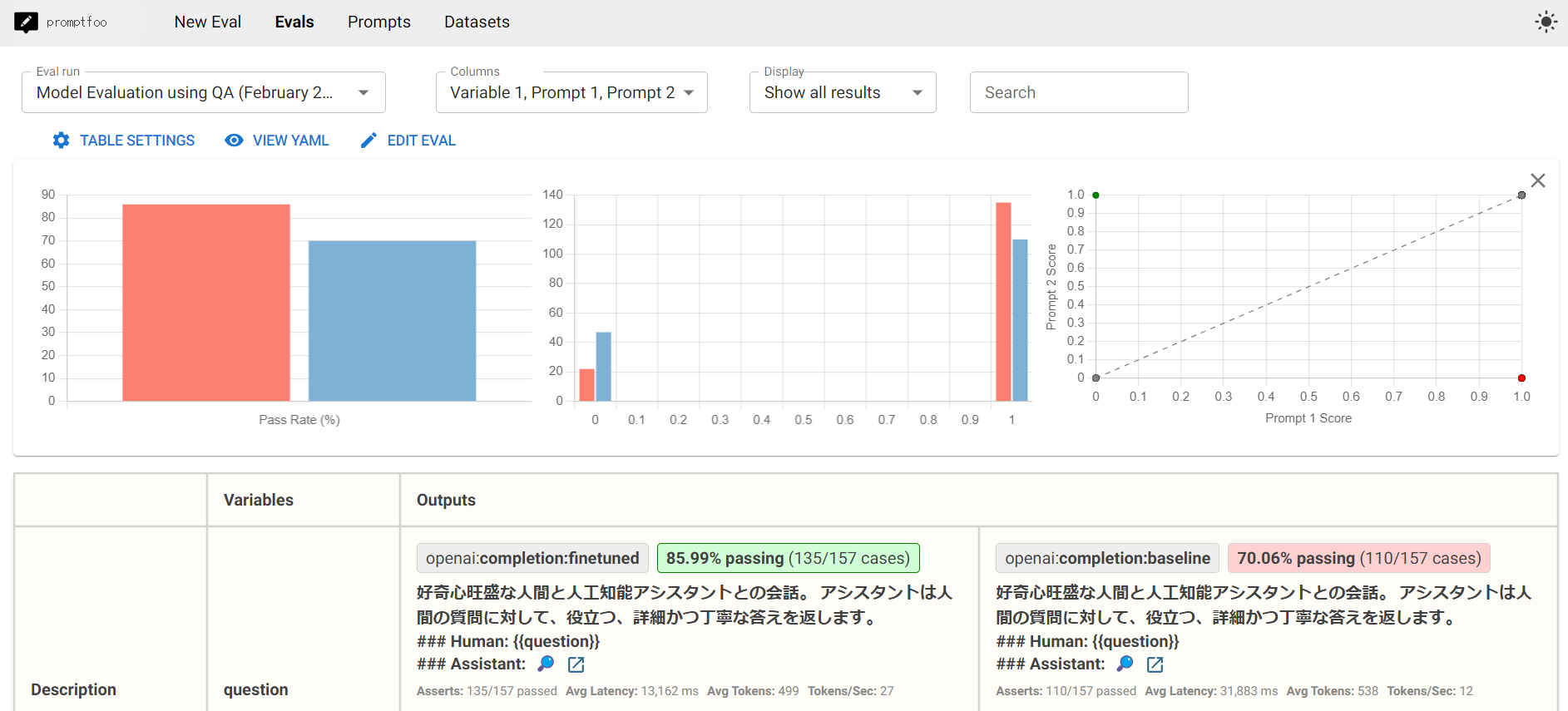
👍ボタンを押すと、NGと評価されていたものをOKに訂正できます。

逆に、👎ボタンを押すと、OKをNGに訂正できます。

また、🔢ボタンを使えば、正答に対する部分点をつけることができます。✏️ボタンでは、コメントを残すこともできます。
人力評価が完了したら、コンソールのログに、評価結果が更新されたことが評価IDとともに表示されているはずです。
$ promptfoo view
Updated eval with ID eval-<YYYY-MM-DD>T<HH-MM-SS>
この評価IDの結果を集計をするには以下のコマンドを実行してください。(IDは複数指定可)
$ python scripts/manual_eval_tools/summarize_promptfoo.py eval-<YYYY-MM-DD>T<HH-MM-SS>
eval-<YYYY-MM-DD>T<HH-MM-SS>
openai:completion:finetuned : 85.9873 %
openai:completion:baseline : 70.0637 %
次にやること
パイプラインを自動実行するチュートリアルを導入すると、より効率的に開発が進められるかもしれません。 もっとモデルを改善するためには、各種のハウツーも試してみましょう。